
In the real estate industry, rent rolls are key documents used for valuing properties and for evaluating their commercial health. For example, high rents, low vacancy, and long tenure indicate good health; low rents, high vacancy, and short tenure indicate poor health. Companies in the prop tech space need this sort of data to build solutions such as automated rent collection and billing, rent trend analytics, and property ROI analytics. However, they often lack access to rent rolls in any format other than PDFs, which makes data extraction a potentially difficult problem.
Enter Sensible, which offers intelligent document automation. With Sensible you can easily extract key information out of documents using SenseML, Sensible’s query language. SenseML uses a combination of layout-based rules and LLM prompts to extract from the full spectrum of free-form to structured documents. We’ve written a library of open-source SenseML configurations, so you don’t need to write queries from scratch for common documents. From there, the document data is accessible via Sensible’s API, SDK, app, or 5,000 other software integrations thanks to Zapier.
What we'll cover
This blog post briefly walks you through configuring extractions for rent rolls. By the end, you’ll know a few methods for extracting document data using our query language, and you’ll be on your way to extracting any data you choose using our documentation or our prebuilt open-source configurations.
Write document extraction queries with SenseML
Let's extract data from a rent roll. Here's an example of a rent roll PDF with redacted or dummy data:
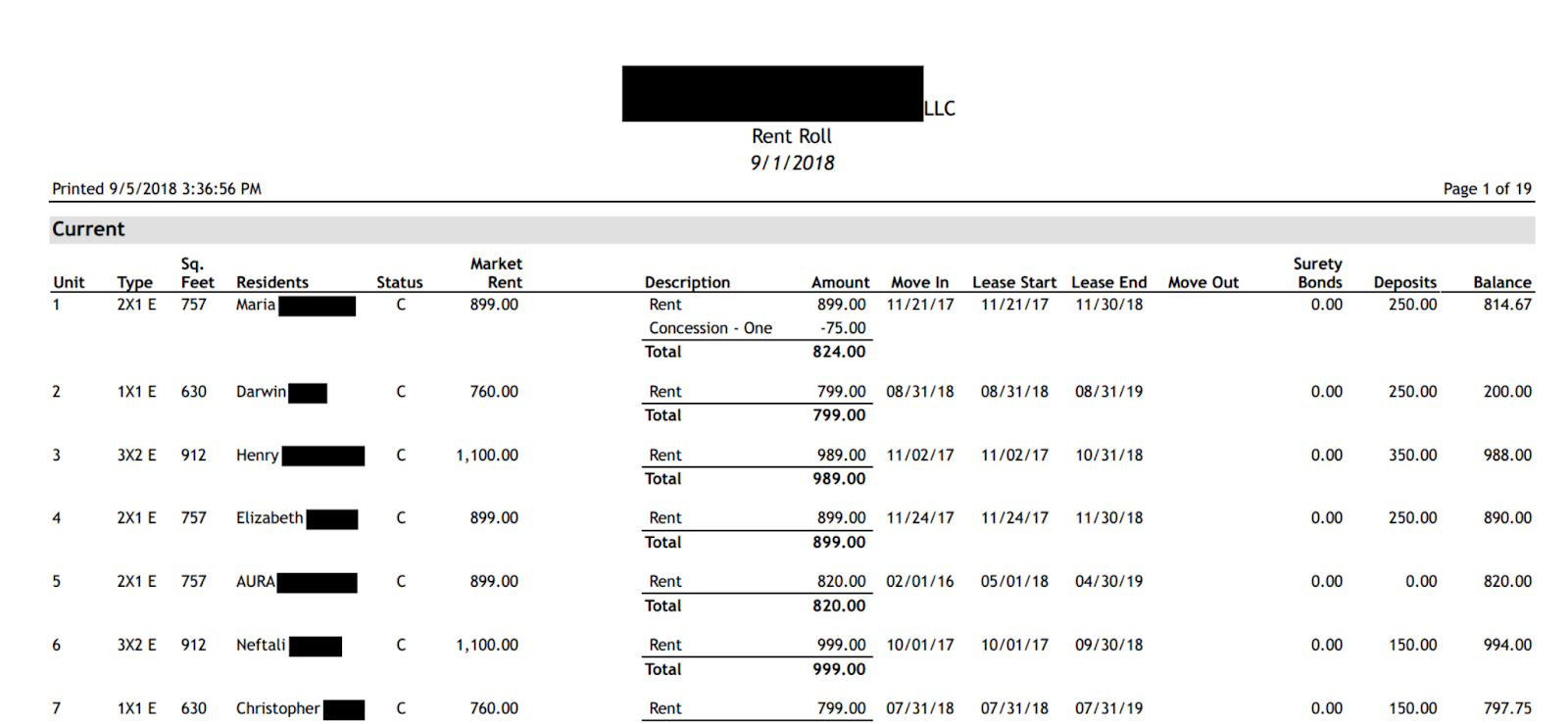
To extract from this document, take the following prerequisite steps:
- Sign up for a Sensible account
- Add prebuilt extraction support for rent rolls to your Sensible account. To add support, follow the steps in Out-of-the-box extractions for rent rolls.
Our configurations for rent rolls are comprehensive. To keep the example in this post simple, let's just extract:
- Total units, total rent, and % occupied
- Apartment complex name
- Details about each apartment unit, such as the occupant’s name and their monthly rent
We’ll also write some logic to test the monthly rent amounts, to verify that the extraction is working properly.
Extract clustered facts: total units and total rent
Since rent rolls are documents with highly variable layouts, let’s use LLM-based methods to extract the data. By asking the LLM questions such as grand total occupied units, you’ll extract facts as structured data. To improve accuracy and performance, you’ll group together facts that always appear in a cluster together in documents.
See the following screenshot for an overview of how to configure a group of LLM prompts that extract a cluster of co-located facts. In this case, they’re on page 18 of the example document:

You can also view this data in JSON view:

To configure the LLM prompts as shown in the preceding screenshot:
- Navigate to the prop tech document type you created in a previous step. This document type contains everything you need to extract from rent rolls.
- For the purposes of this tutorial, you’ll create a blank test configuration in the document type. Click Create configuration and name it test_rents.
- Click the configuration you created to edit it.
- Switch to the JSON editor view by clicking Switch to SenseML. The app displays an example rent roll in the middle pane and the empty configuration in the left pane.
- Paste the following code into the left pane of the Sensible app.
You'll get this output in the right pane:
In the preceding output, the confidenceSignal is a more nuanced alternative to confidence scores that indicates whether the LLM judges its own answer to be correct.
Extract a standalone fact: apartment complex name
In unstructured documents, some facts aren’t consistently co-located with other facts. For example, the apartment complex name in rent rolls lacks a pattern of co-located facts. To handle this, let’s put it in a single-query group.
See the following screenshot for an overview of how to extract the apartment name:

To try this out yourself, paste the following query, or "field" into the left pane of the Sensible app in the fields array:
Since the apartment name is redacted in the example document, you’ll get back the text "LLC".
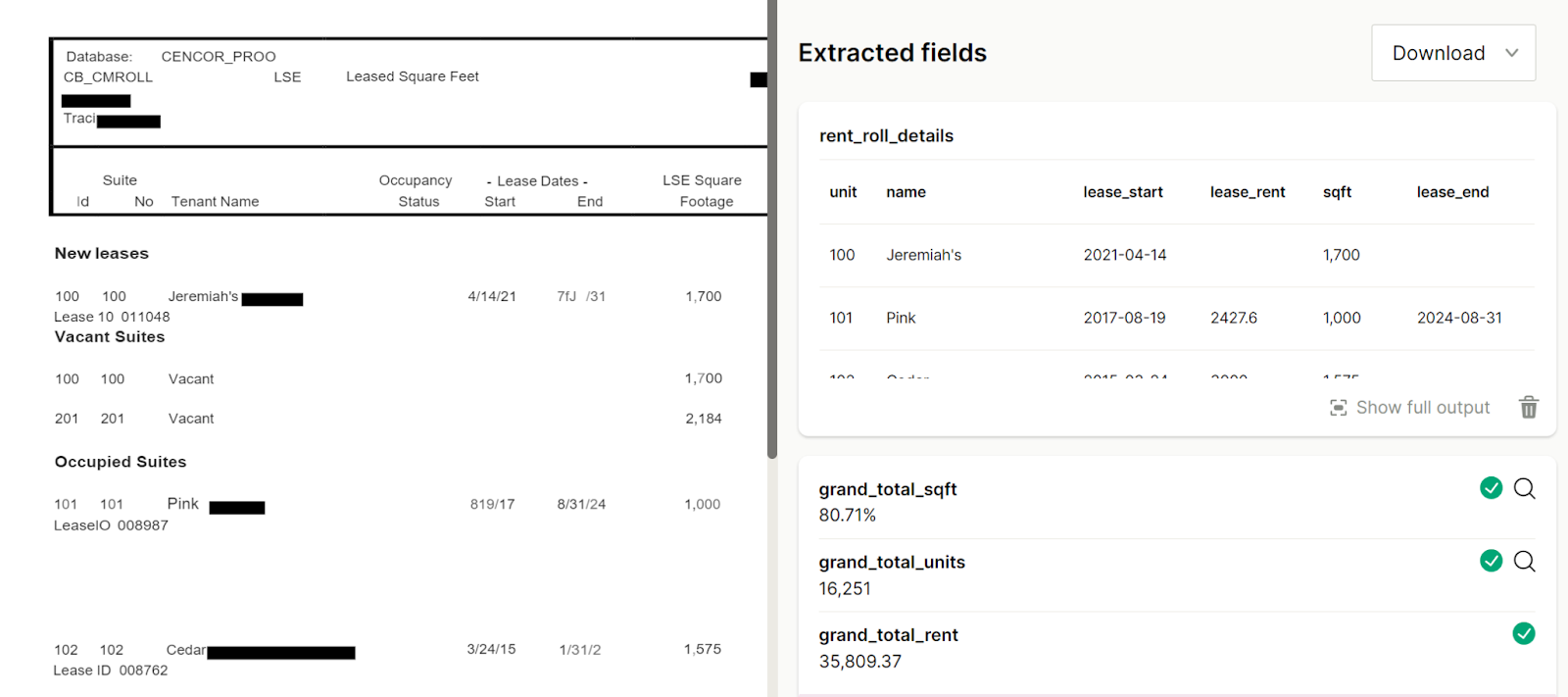
Extract repeating data: lists of rent details
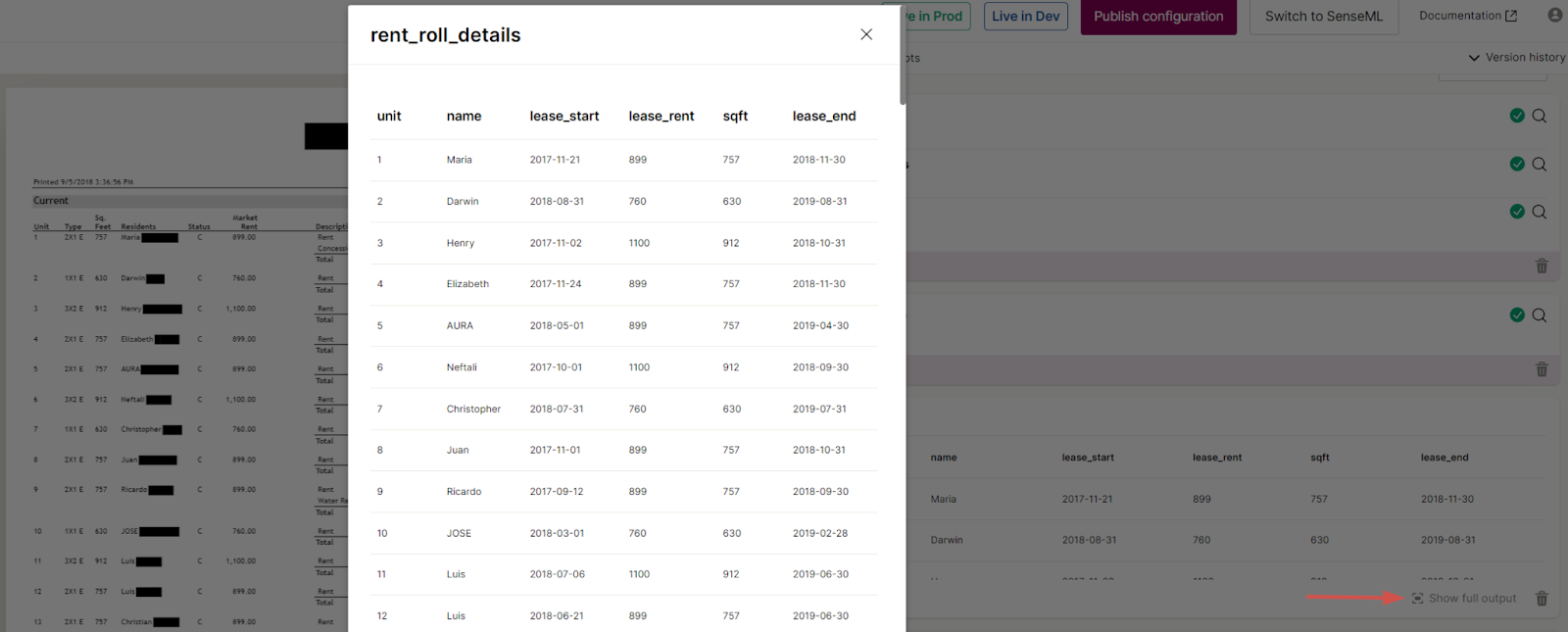
In the example document, there’s a list of rent details. For each unit in the apartment complex, the document lists details such as the unit number, type, occupants, and market rent. To extract this repeating data, use the List method. The List method describes the list’s overall contents (rent_roll_details) and each item that repeats in the list (unit, name / occupant, etc).
See the following screenshot for an overview of extracting the rent details mentioned in the rent roll:

Click Show full output to see the full list:
To view the same data as JSON, click Switch to SenseML:

To try this out yourself, paste the following query, or "field", into the left pane of the Sensible app in the fields array:
NOTE: The List method can take several minutes to return results when you set the LLM Engine parameter to thorough.
You’ll get output like the following (truncated):
Transform extracted data: Validate rent amounts
In the example document, there are data-entry errors. See the following screenshots for examples of these typos:

In previous steps, you prompted the LLM to handle typos with the instructions "ignore whitespaces in number". However, the LLM is indeterminate and can still interpret a typo like 3 768,43 as the number 3. Since it’s unlikely that an occupant has a monthly rent of $3, let’s validate that extracted rents are all over a reasonable baseline number, say $100. Let’s return rent "not found" if the rent amount is null.
To try this out yourself, paste the following query, or "field" into the left pane of the Sensible app in the fields array:
Switch back to Sensible Instruct to view the output as a table:

All the rents in the preceding screenshot returned true for is_rent_over_100_dollars. You can write then validations to return error messages on document extractions if a field returns false for this condition.
Test the extraction template with a second document
You can use the extraction queries, or fields, you authored in previous steps to extract from other documents. To try it out:
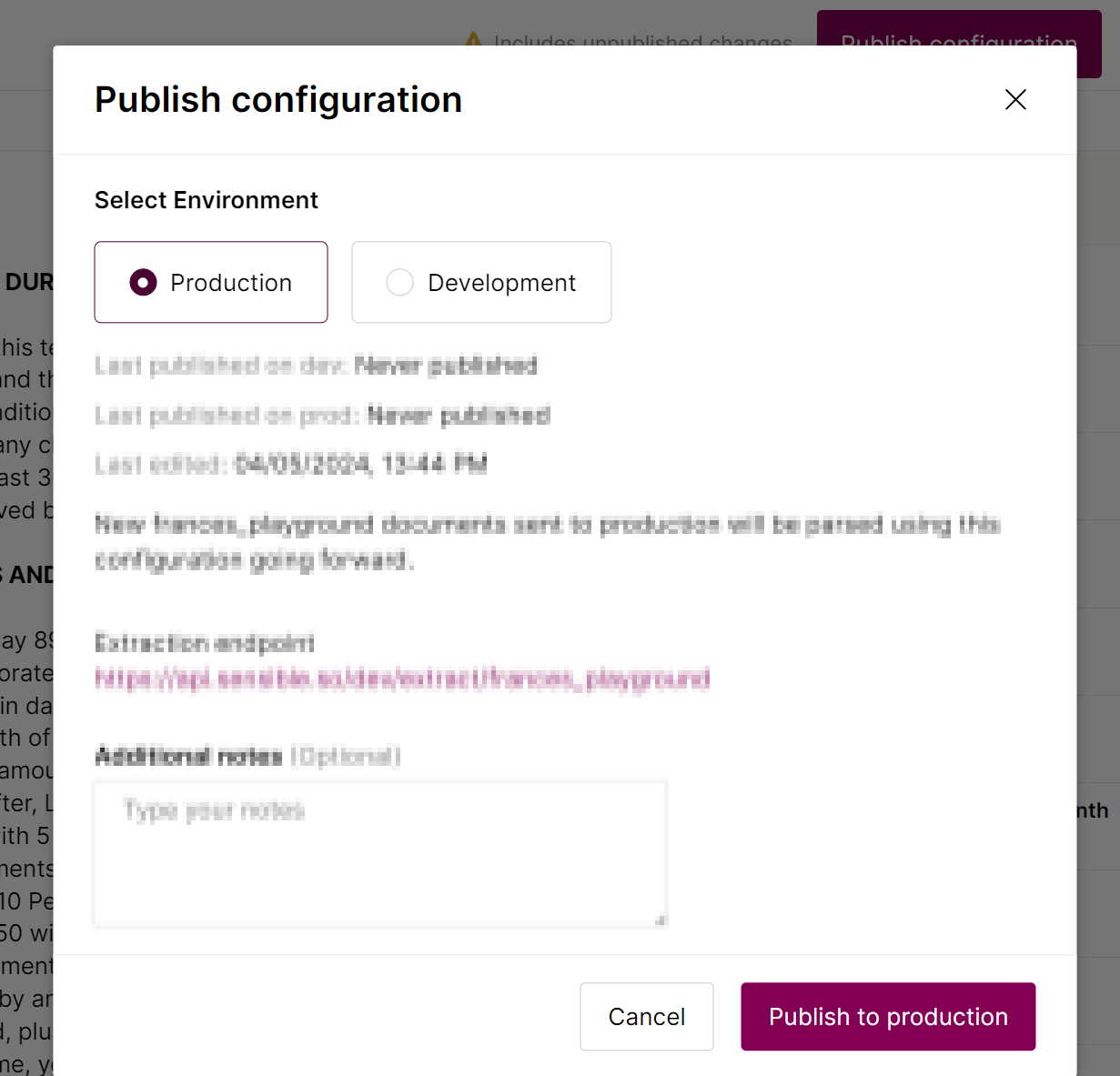
- Publish your template by selecting Publish configuration > Publish to production:
- Download the second example document: Download link
- Upload the second example document by clicking Add file in the Sensible Instruct editor view:
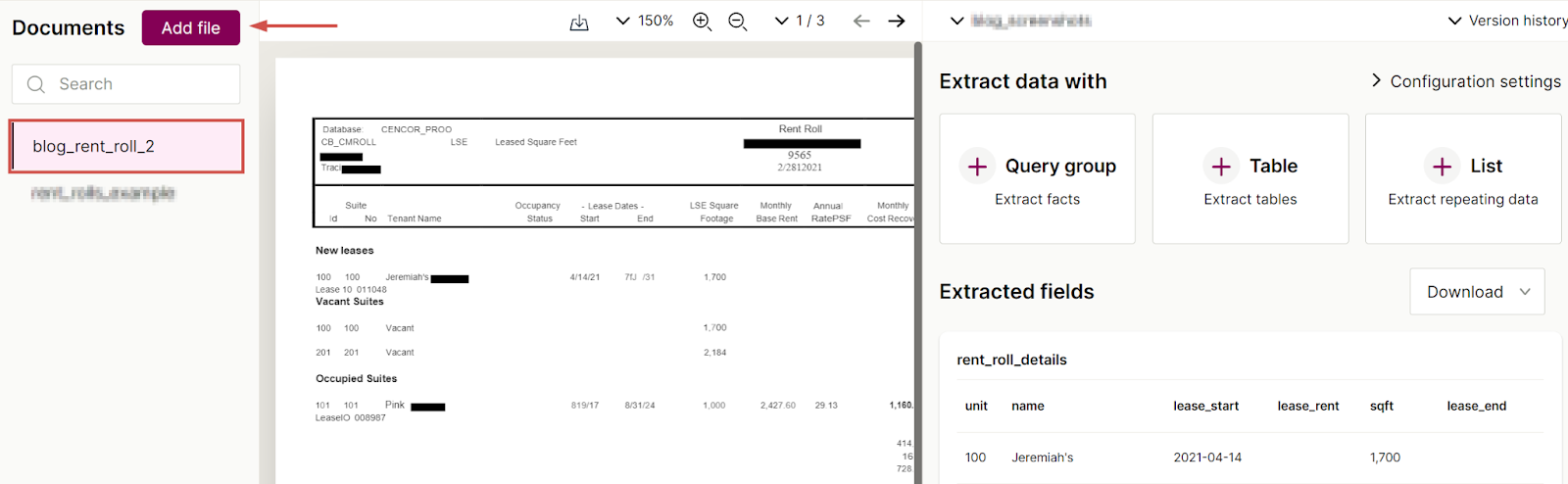
Note that the extracted data in the right pane updates to reflect the new document:
Extract from your documents
Congratulations, you’ve learned some key methods for extracting structured data from rent rolls. To start extracting from your own rent roll documents:
- Use our pre-built support for rent rolls to extract more comprehensive data than covered in this tutorial. To explore the support, open the rent_rolls configuration, and start uploading your own documents to test against this config.
- Integrate rent roll document extractions in volume using the Sensible API, SDK, or bulk-upload UI.
Advanced extractions
We offer advanced configuration for LLM prompts, so you can extract facts, lists, and tables from even the trickiest document. You can extract from non-text images embedded in documents using multimodal LLMs such as GPT-4 Vision. And if an LLM can’t extract the data you’re looking for, you can always fall back to Sensible’s layout-based, deterministic extraction methods.
Try it out for free
There's more extraction power for you to uncover. Sign up for an account (no credit card required), check out our prebuilt configs in our open-source library, and peruse our docs to start extracting data from your own documents.

.png)
