



For many engineers and data scientists, there comes a fateful day when you need to extract structured data from PDFs. To the consternation of your less technical peers, this is quite difficult to accomplish, and right out the gate you have a choice: do you use OCR or extract text from the PDF directly?
In some cases you don't have a choice — your PDFs are document images containing no underlying text data. For PDFs with embedded text, however, the benefits of avoiding OCR are plentiful. You eliminate entire classes of error (unrecognized text, character classification errors, and spatial jitter), your text extraction takes milliseconds instead of many seconds, and the cost is near zero vs ~.15 - 1.5 cents per page.
These advantages can be the difference between success and failure for your use case. An accurate extraction from a 47 page insurance policy in 2 seconds is useful for a user-facing workflow, whereas a buggy extraction in 32 seconds is not.
Unfortunately, direct text extraction from PDFs comes with its own set of challenges, as our friends at FilingDB have thoroughly catalogued. You may find:
- Over-split and under-split lines
- Ligatures
- Hidden text
- Text embedded in images
- Extra spaces or missing spaces
At Sensible we've seen all of these issues in real world documents spanning the insurance, logistics, financial services, and government domains. Let's dig in to how to overcome them.
The data model
The baseline approach to finding target data in a PDF is to dump its text contents to a string and apply regular expressions to isolate the target data. This can be effective in some scenarios (particularly if you just want to know if a document contains, say, credit card numbers or SSNs), but it's quite brittle and you're dropping a bunch of document information on the floor. We suggest an approach that maximizes information retention — you retain the spatial layout, sizing, and raw pixel data from the document as you transform it into structured data.

Your document representation is therefore an array of pages, each of which has an array of lines of text. Each line is a string with a bounding box (strictly, a bounding polygon) in 2D space on the page. In addition, you can render each page to get its pixel data if necessary, and store additional metadata like the font family. Here's an example of how such a representation might divide text into lines (gray rectangles):

There are two notable open source projects that will help you get to this representation from a PDF:
Both these libraries are excellent and we at Sensible are forever thankful to their maintainers for navigating the wild and wooly world that is the PDF file format 🙏
The above all sounds great (hopefully), but there's some lurking ambiguity. Let's delve into the problems you can encounter.
Over-split and under-split lines
Under the hood, PDFs do not represent their text as lines or words, but rather as individual characters to draw at specific locations on a page. The net effect is to create words, lines, and paragraphs that are easily interpretable to the human eye. Programmatically these constructs are less obvious: you need to infer them from the raw drawing commands.
Both PDF.js and PDFBox have built-in logic to group characters into lines, but this logic often does not match with the organization we perceive when viewing the document. OCR output has a similar challenge, particularly with handwriting.
There are two ways this manifests: lines that are over-split (multiple lines when there should be one) and lines that are under-split.
Solving over-split lines
The over-split case is the trickiest. You need to determine whether to merge any two lines, and if so, whether to insert a space between them.


Here at Sensible, we've had success with a spatial threshold-based policy for merging. There are two key thresholds:
- Y-axis overlap: the portion of the total y-axis extent of both lines that is occupied by both lines
- X-axis gap: the distance between the right edge of one line and the left edge of another
If two lines have sufficient y-axis overlap and a low enough x-axis gap you merge them without a space, and with a slightly higher x-axis gap you merge with a space.

In practice a y-axis overlap threshold of ~0.8 (where 1 is perfect overlap) works well, and it's helpful to define the x-axis gap as a proportion of text height (0.15 and 0.6 are good defaults for no space and with space merging, respectively).
The other thing to keep an eye on with these merges is computational complexity. Since a merge can impact future merges, a naive algorithm can easily be O(n^2) or worse. Typically the number of lines on a single page is not super high, but it's still good practice to use efficient spatial lookups to constrain your candidate lines. Flatbush is a nice package in Javascript for doing this.
Solving under-split lines
The under-split case is most common in monospaced documents that use spaces for their layout. Think of creating a table using a typewriter.
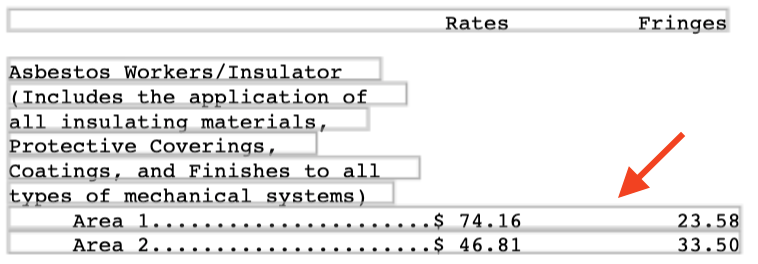
Here you can just split lines on some minimum number of spaces (three is a good bet to dodge docs that use two spaces after periods) and recover higher quality layout data. Happily, updating the constituent bounding boxes after a split is trivial with a monospaced font.
Ligatures
Sometimes you'll see what first appear to be garbage Unicode characters in your direct text extraction. Here's an example of some raw text from a home inspection report:

Those escape sequences appear to be the Unicode null character, but are actually ligatures: two or more letters joined into a single glyph. In these documents fi, fl and others are joined together and appear as \u0000 in the raw text, so that you see \u0000re instead of fire and over\u0000ow instead of overflow.
There's a simple solution in some cases. If you have a unique escape sequence for each ligature, you'll have a 1-1 mapping and can easily perform a replacement.
But in the preceding case, the mapping isn't unique, since fi and fl both map to \u0000. In such cases the PDF renders correctly, so somewhere in the rendering pipeline unique ligature characters are recoverable. But unless you want to delve into the internals of the package you're using to extract text (or switch packages), it may be easier to infer the mapping. You may also not know the mapping ahead of time. To infer the mapping you can:
- Score possible replacements based on character transition probabilities (i.e., i is much more likely to precede an m than an f is) and choose the most likely replacement.
- Take a more conservative approach and use a dictionary in the target language to choose replacements that lead to known words, which may leave you with some Unicode characters in proper names or other non-word data.
Hidden text
PDFs may contain text that is not visible in the rendered document. This text may be white on a white background, covered by an image or other graphic element, or positioned off the page. Regardless, it will be a surprise when you see it in your output.
Spatial relationships to the rescue
If you identify your target data using their spatial relationship to other lines, you're less likely to capture hidden text than if you simply use regexes on a raw text dump. For example, you might look for lines that are left-aligned under a label. One of the benefits of direct text extraction is that we get precise positioning data for each line, so filtering based on text alignment can be quite strict and effective in suppressing noisy data.

Scanned docs with garbage text
One particularly pernicious source of hidden text is in scanned documents. Under the banner of searchability, some document scanners will embed gibberish OCR output underneath the scanned image of the document. When you view this document you won't see that text, but it is present in a direct text extraction.
In this case (as with any scanned document) the only way to recover usable text is to fall back to OCR. But how can you judge if a PDF needs OCR in this case? The typical method of identifying scanned PDFs by their lack of embedded text won't work here, because embedded text is present in the scan. There are a couple of approaches here:
- The simplest approach to detecting this case is to render the PDF and detect whole-page images — if the document has a good proportion of such images, it's likely a scan. Depending on the PDF, this can add an unacceptable amount of processing time to your extraction. Even rendering a single page can take a few hundred milliseconds.
- A faster approach is to score the embedded text on the likelihood that it is not gibberish. You can do dictionary lookups on the words in the embedded lines and threshold on the proportion of hits. An alternative (and more language agnostic) approach is to score each word on whether it's purely composed of alphabetical characters or if it has a mix of alphanumeric characters and symbols, which is a hallmark of poor OCR.
Text embedded in images
Some PDFs amble merrily along with high-quality embedded text, and then in the middle of the document a key section is represented by an image. We've seen this in insurance policies where the core coverage details look like perfectly normal text, but as you zoom in, your eyes widen in horror as the text blurs.


Here you need to use OCR, but running OCR on the whole document would lead to higher cost and slower performance. The approach we take in these cases is to selectively OCR just those pages with text images in them:
- In a fixed document format you can do this at a specific page offset, rendering the page and sending it to a synchronous OCR endpoint.
- For variable document formats you can match surrounding non-image text and then page offset from those anchor points to determine which page has the data you want.
For your OCR engine, the best options in this scenario are AWS Textract and Google Document AI. Both have synchronous and asynchronous APIs. The synchronous APIs are page count limited but much faster (low seconds for sync vs tens of seconds for the async calls). Microsoft Form Recognizer has high quality output (it does the best job at grouping words into lines in our experience) but only offers an async mode and thus is a bit slow for these single page use cases. If you go the open source route, Tesseract is a good place to start.
Extra spaces and missing spaces
Errant whitespace is fairly common in PDFs. As a baseline you'll want to deduplicate spaces (after potentially splitting lines on them as above) and trim all your lines. After this cleaning you may still have extra spaces (within a word, say) or missing spaces (between words) in your lines.
The best strategy for dealing with noisy whitespace differs depending on whether you're attempting to find specific phrases in your text, or extract an unknown value.
Specific phrases
If you're searching for lines containing the phrase "heating furnaces" and the extracted text is "heatingfurn aces", you won't find your match with a strict comparison. Instead you can perform a fuzzy comparison based on the edit distance between your target phrase and the line. The edit distance between two strings is the number of modifications you need to make for the strings to be identical. For example, the string "heating furnaces" has an edit distance of two from "heatingfurn aces" because you need to either insert or delete two spaces to make those two strings equal. There are several edit distances that differ in the types of modification they allow:
- For the purposes of solely dealing with errant whitespace, the longest common subsequence (LCS) distance is best as it only allows insertion and deletion.
- For dealing with OCR character classification and whitespace errors, Levenshtein distance is best as it also allows substitution. Natural is a good open source project in Javascript with implementations of Levenshtein distance and other fundamental NLP techniques.
Values
Values are trickier:
- If you're looking for data of a particular type, like dates or currencies, you can often make your type extraction resilient to missing or extra whitespace by stripping out all whitespace.
- For free text, we've seen good results using NLP engines like OpenAI's GPT-3 to clean the output for free-text documents. GPT-3 has notable limitations in total input size and it will add some delay to processing, but its results are often indistinguishable from human.

It's worth it
If all of the above sounds a bit painful, well, it is. Nevertheless, the performance, cost, and accuracy advantages make direct text extraction well worth your while for many use cases. OCRing the world puts a strict ceiling on the quality and speed of your document processing solution; direct text extraction imposes no such limitations. And fortunately there are billions of PDFs out there that are relatively well behaved when it comes to text extraction, with few if any of the above issues.
If you'd like the benefits of direct text extraction without all the headaches, at Sensible we've built developer tools that give you most of the above out of the box. Our document query language, SenseML, will get you from PDFs to structured data in hours, not days or weeks. If you've run into these challenges, sign up for a free Sensible account (100 documents a month, no credit card required).

.png)
