

In construction, labor compliance isn't optional. Prevailing wage laws, certified payroll requirements, and regulatory reporting demand precise documentation of every worker's hours, wages, and job classifications. For companies managing compliance across multiple projects and contractors, the data locked inside payroll reports is essential—but extracting it at scale can be an incredibly challenging task.
One construction compliance software company learned this the hard way. After evaluating vendor after vendor, they'd almost given up on automated payroll extraction entirely. But after evaluating Sensible, they began to realize their difficult use case could be addressed.
The challenge: Documents that defeated every solution
The company's product helps construction firms track labor, payroll, prevailing wages, and man-hours while generating regulatory reports. When these firms onboard as clients, they need to import historical payroll data. That often means processing dozens of reports from various contractors, each with their own formatting quirks.
The documents presented a perfect storm of extraction challenges. Many payroll reports start as standardized templates that contractors customize with added fields, adjusted labels, or freetext. These edited PDFs create downstream chaos: text that looks perfectly readable to human eyes becomes mysteriously illegible to OCR. On top of that, payroll reports pack enormous amounts of data into compact tables, where worker names, hours, wage rates, and deductions crowd together in cells so small that OCR engines frequently merge adjacent values into garbage.
When documents are scanned rather than digital, low contrast, slight blurs, and compression artifacts compound everything further. And perhaps most frustratingly, payroll reports that look nearly identical can behave completely differently. A data-extraction configuration that works perfectly for one fails catastrophically on the other.
The company had tested multiple extraction vendors. None could handle the complexity. They'd resigned themselves to manual data entry.
The solution: Hybrid extraction with surgical precision
Layout-first for structure
The core data extraction relies on deterministic layout-based methods. Payroll reports follow predictable structures: header information at the top, followed by detailed tables of worker data. Layout methods excel at navigating this structure reliably, even when OCR quality varies.
Splitting text to survive merging
One key technique: using a preprocessing step that splits text aggressively, breaking every word into its own line. This prevents the OCR merging problem where adjacent values in dense tables get combined into nonsense. The tradeoff is that some layout logic becomes harder to express, which is where LLM methods come in.
LLMs for the impossible spots
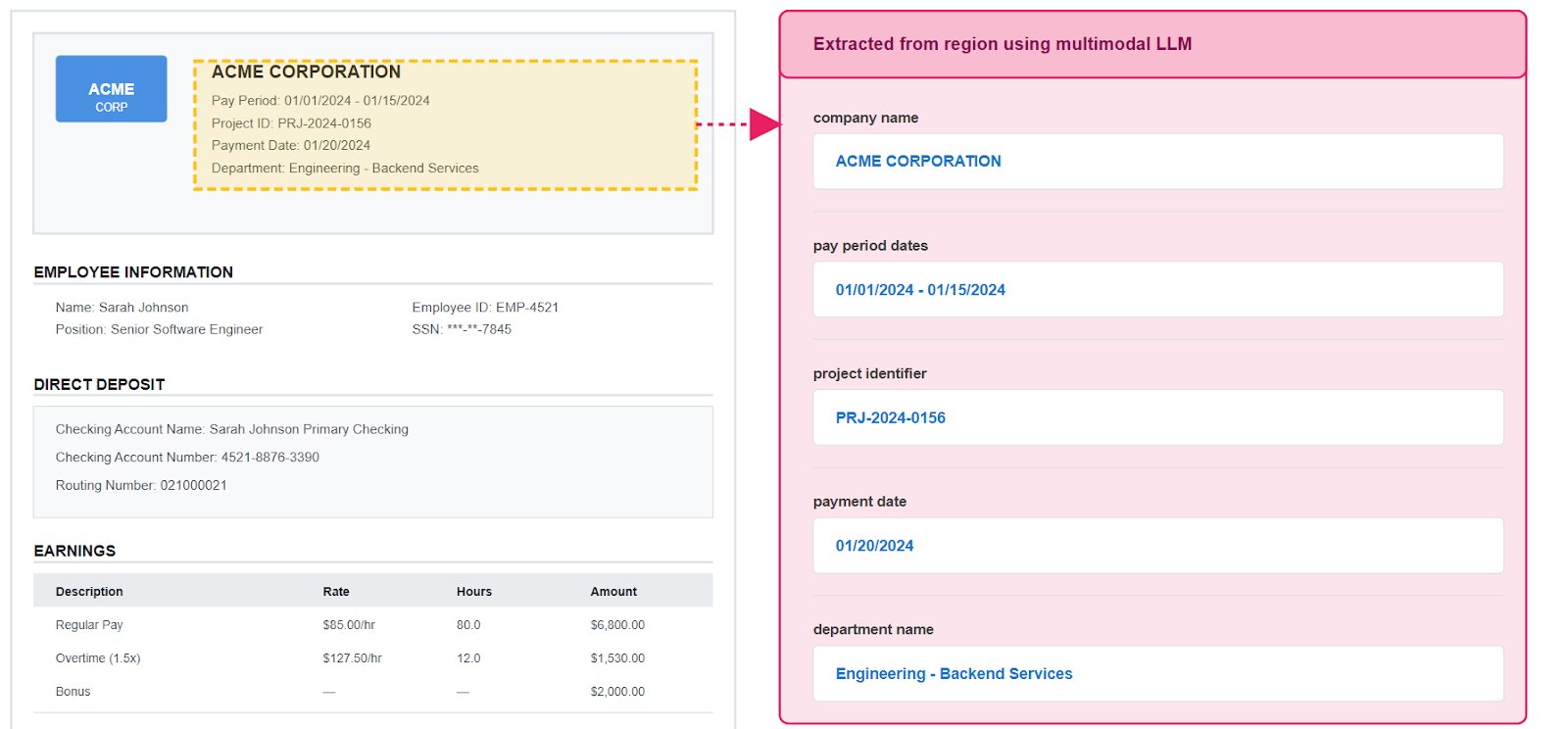
When OCR simply cannot read a region, there’s a fallback multimodal LLM extraction approach. First, define a bounding box using deterministic layout text anchors (generally headers), then let the LLM interpret just that region. This keeps extraction predictable while handling spots that would otherwise require manual review. For example, in the following image, the extraction deterministically anchors on “ACME CORPORATION”, defines a rectangular region in inches, and then prompts the multimodal LLM to extract the data in the region.
Custom configurations per customer
Rather than fighting to build universal templates, the team builds custom data extraction configurations for each new customer the company onboards. This usually means about a dozen configurations total, with about half covering reports that look nearly identical but have different underlying PDF behaviors. The company routes documents directly to specific configurations rather than relying on auto-classification, ensuring each document hits the right extraction logic.
The results: From impossible to operational
Sensible now processes payroll reports for the company that no other vendor could handle. Issues that arise get resolved quickly, often within a day rather than within weeks of back-and-forth. The documents remain genuinely difficult, and some manual verification is still necessary. But the comparison that matters isn't perfection versus imperfection. It's automation with exceptions versus pure manual entry.
More importantly, the company can now offer a capability they'd previously abandoned. Automated payroll import went from "impossible" to a functioning product feature.
Key takeaways for difficult document extraction
- Hybrid methods exist for a reason. Pure LLM approaches struggle with dense tabular data; pure layout approaches struggle with OCR failures. Combining them strategically often succeeds where either alone fails.
- Sometimes universal templates aren't the answer. When document variants behave unpredictably despite looking similar, customer-specific configurations may be more practical than fighting for a single solution.
- Preprocessing can save extraction. Techniques like aggressively splitting text can address problems at the OCR level before extraction logic even runs.
"Good enough" beats "impossible." A solution that handles 90% automatically with 10% requiring review is far better than 100% manual entry.
.png)

