



In healthcare, document processing carries unique stakes. Whether it's determining donor eligibility or ensuring the right specimen reaches the right lab, accuracy and speed are vital.
Two healthcare organizations recently implemented Sensible to automate their document workflows. Both process medical documents. Both prioritized speed and accuracy. But their paths to production differed markedly. One built 50+ extraction configurations entirely on their own, declining even a product demo in favor of self-serve. The other partnered closely with Sensible's team to tackle the unique challenge of handwritten, scanned forms. Their stories illustrate the spectrum of implementation approaches available when automating document extraction.
Company A: Self-service at speed
Company A operates in the organ and tissue banking space, working with cardiac device reports as part of donor screening. When a potential donor has an implanted cardiac device, the device's data report becomes a critical piece of documentation that needs to be processed quickly and accurately.
The challenge: Build it themselves, on their terms
Company A knew exactly what they wanted: a platform they could master independently. During their vendor evaluation, they assessed multiple solutions with one primary criterion in mind: could they do this themselves without relying on external support?
When Sensible offered a customized demo, they politely declined. They wanted to figure it out on their own.
The solution: Rapid self-service deployment
Company A's implementation became one of the fastest paths to production Sensible has seen. Entirely self-service, they rapidly built between 30 and 60 layout-based extraction configurations.. Each configuration handles a specific format from one of the four or five medical device manufacturers whose reports they process.
The configurations themselves are straightforward: fewer than 20 high-level fields per document, pulling specific data points from tables rather than extracting entire table structures. No complex normalization or transformation logic required.
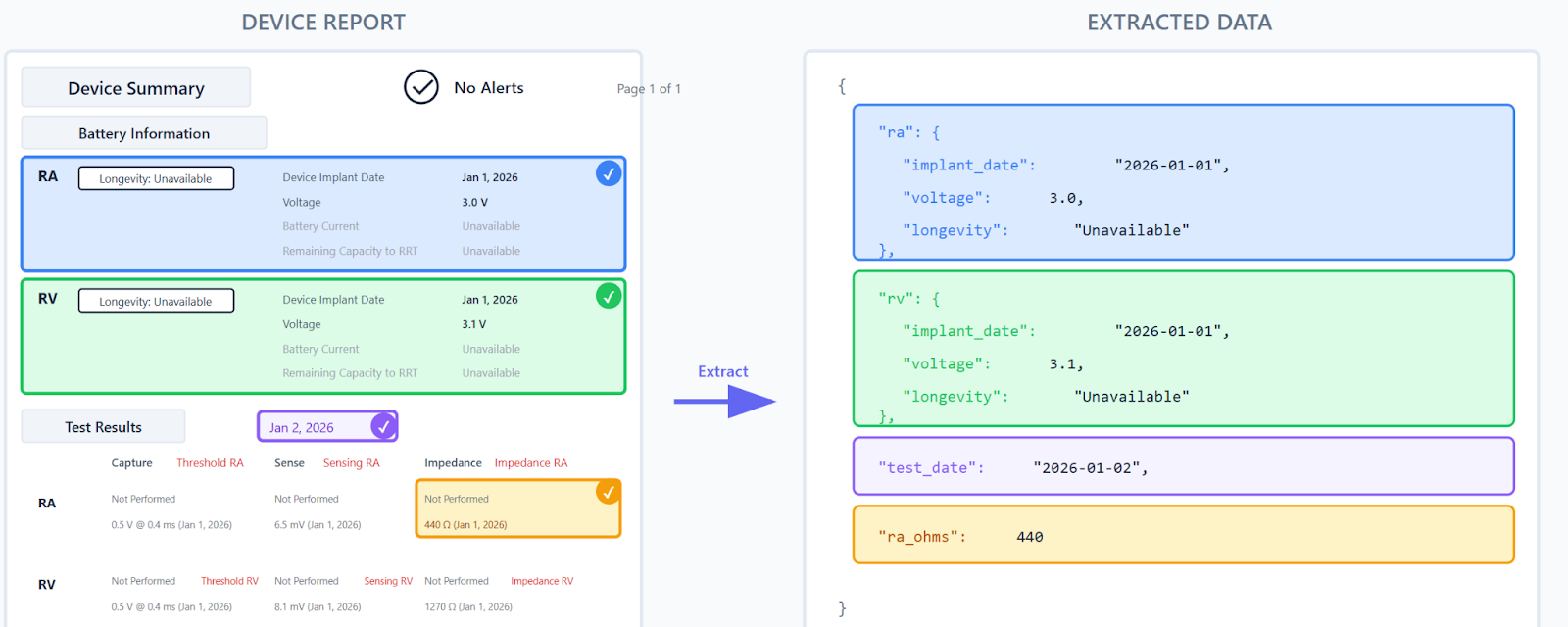
Their account structure reflects a methodical approach: configurations organized by device manufacturer, then by specific device type (dual chamber, single chamber, leadless, and so on). In some cases, they created more configurations than strictly necessary (many could have been consolidated with conditional logic) but the granular approach worked for their workflow.
Why layout-based extraction? Company A valued the transparency and determinism it provided compared to LLM-based extractions. They could see exactly how data was being extracted, understand why a configuration worked or didn't, and fix issues themselves. For a team that wanted complete independence, that transparency was essential.
The results: Production-ready in record time
Company A reached production faster than almost any customer Sensible has worked with. They built dozens of highly accurate configurations without requiring hands-on support. The only significant intervention came months later when a subset of documents began failing. The issue turned out to be OCR-related. Sensible used an OCR engine from Microsoft by default, which struggled with certain poor-quality scans. The fix was simply to switch those specific configurations to Amazon's OCR engine. Sensible's platform allows different OCR providers per document type, so Company A could address the problem surgically without disrupting their other workflows.
Today, they process documents at high volume with minimal ongoing support. It’s exactly the relationship they wanted from the start.
Company B: Partnership for precision
Company B is a pathology laboratory whose primary service is processing surgical specimens and delivering professional interpretation reports. Before analysis can begin, every specimen arrives with a requisition form. This formal request from a healthcare provider documents what tests to perform and on which patient.
The challenge: Handwritten forms at high volume
Company B's requisition forms presented a classic document processing challenge. They were handwritten, scanned, and arrived in high volume. During a recent month that included a holiday slowdown, they processed over 1,300 forms. On typical business days, they handle roughly 100 forms daily.
Before automation, staff processed these forms manually. At that volume, manual entry wasn't just tedious, it was a constraint on how quickly specimens could move through the lab. But automation had to be fast. If extraction took more than a few seconds, technicians would simply do it by hand rather than wait.
The forms themselves added complexity. Healthcare providers don't always write clearly. A biopsy location might be marked "L", "LT", or "Lt" when indicating "left." Patient metadata needed to be accurate. And scan quality varied significantly.
The solution: Deterministic extraction with smart normalization
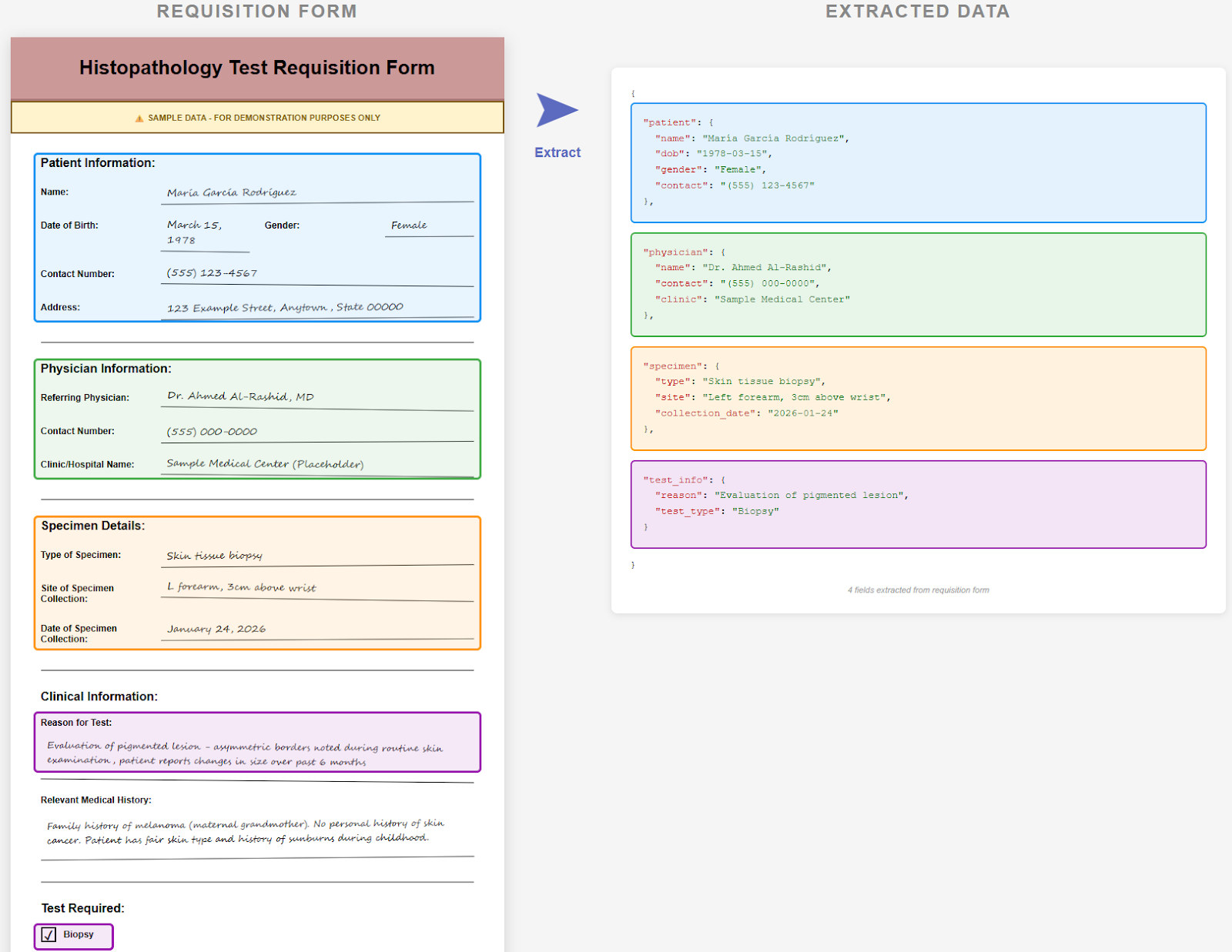
Company B partnered with Sensible's team to build extraction configurations that could handle the messiness of real-world medical forms. The approach was primarily deterministic, layout-based methods that deliver consistent results.
A key implementation detail involved normalization logic. Using Sensible's compose and replace features, the team built transformations that convert handwriting variations into standardized outputs. All those different ways of writing "left"? They all normalize to "Left" in the final extraction. This kind of transformation ensures downstream systems receive clean, consistent data regardless of how the original form was filled out.
Amazon's OCR engine proved effective even with challenging handwriting, including cursive. For the longtail of scan variations, the team also built a generalized configuration using multimodal LLM capabilities (though speed constraints mean it's still being evaluated for production use).
The implementation focused on what mattered most: patient metadata and specimen details. The schema is relatively simple, but accuracy is non-negotiable. Currently, two or three form formats handle the bulk of their volume.
The results: Speed that makes automation worthwhile
Company B now processes requisition forms in seconds fast enough that automation actually saves time compared to manual entry. That threshold—extraction in seconds, not minutes—was the entire point. If the system couldn't beat a technician typing data by hand, it wouldn't get used.
The normalization logic solved a problem that would have created downstream headaches: inconsistent data from inconsistent handwriting. By standardizing outputs at extraction time, Company B's backend systems receive clean data without additional processing..
Two paths, one platform
These implementations reveal the full spectrum of how organizations can approach document automation:
Company A optimized for independence. With straightforward documents and a team eager to own the solution end-to-end, self-service was the right fit. They built fast, learned fast, and reached production with minimal external involvement.
Company B optimized for accuracy under constraints. Handwritten forms, variable scan quality, and strict speed requirements demanded close collaboration to get the implementation right. The partnership model let them tackle edge cases they couldn't have solved alone.
Key takeaways for healthcare document automation
If you're evaluating document extraction for healthcare workflows:
- Match implementation approach to team capabilities: Self-service works beautifully when documents are straightforward and your team wants independence. Partnership models work when edge cases require specialized expertise.
- Plan for OCR variability: Scan quality varies, and different OCR engines handle different document types better. The ability to choose OCR providers provides flexibility when issues arise.
- Build normalization into extraction: Don't push data cleanup downstream. If handwriting variations or format inconsistencies will create problems later, address them during extraction with transformation logic.
- Speed thresholds matter: Automation only works if it's faster than the alternative. For high-volume, time-sensitive workflows, extraction speed can determine whether the solution actually gets adopted.
Book a demo to discuss your healthcare document processing requirements, or explore our managed services to see how we can handle template creation and maintenance for you.

.png)

