



For businesses managing vendor relationships and operational costs, utility and telecom bills are critical data sources. Whether it's verifying that charges align with contracts or building analytics dashboards for clients, extracting structured data from these documents at scale is essential.
Two companies recently partnered with Sensible to automate their bill processing workflows. Both handle highly structured, complex bill documents. Both chose deterministic, layout-based extraction over LLM approaches. But their business needs are a study in contrast. One processes thousands of energy and telecomm bills across 2,000+ carriers, prioritizing schema precision for auditing. The other processes telecomm documents that can stretch to tens of thousands of pages, prioritizing granular data extraction for analytics. Their stories illustrate how the same document type can demand vastly different solutions.
Company A: Expense management at carrier scale
Company A specializes in telecom, utility, and technology vendor management. Their core service involves helping businesses audit charges against contracts, automate payment allocations, and ensure they're not overpaying. Every month, they process approximately 20,000 bills from an enormous variety of sources.
The challenge: 2,000+ carriers and a brittle system
Company A had built an internal solution in C++ to parse bills. It worked…until it didn't. The system was brittle. When something broke, it was "all hands on deck" for days to fix it. Building a new template for a new carrier format could take up to two weeks. With a backlog of formats to onboard and over 2,000 carriers to support, the maintenance burden had become untenable.
"It's one thing if there's two templates causing issues," their team explained. "It's another thing if there's a hundred."
They'd talked to virtually every vendor in the market. What they needed was a solution that could handle massive format variation while delivering data in a precise, predictable schema—and a partner who could share the implementation workload.
The solution: Managed services with complex conditional logic
Company A opted for Sensible's managed services model, establishing a true 50/50 partnership with weekly check-ins. The Sensible team builds and maintains extraction configurations while Company A's team provides detailed specifications for each new format.
The implementation required sophisticated conditional logic to handle the complexity of their schema requirements. For energy bills, the output schema changes depending on whether there's a meter with readings, a single meter, or multiple meters. The team uses conditional logic throughout: if there's a meter, extract data one way; if there's no meter, handle it differently.
One particularly interesting challenge involved spatial discontinuity. Charges appear in repeating sections, and sometimes charges appear in a completely different location on the page from the meters they're associated with. Using transformation logic, the Sensible team built configurations that correctly associate charges with their parent meters even when they're not spatially nested in the document.
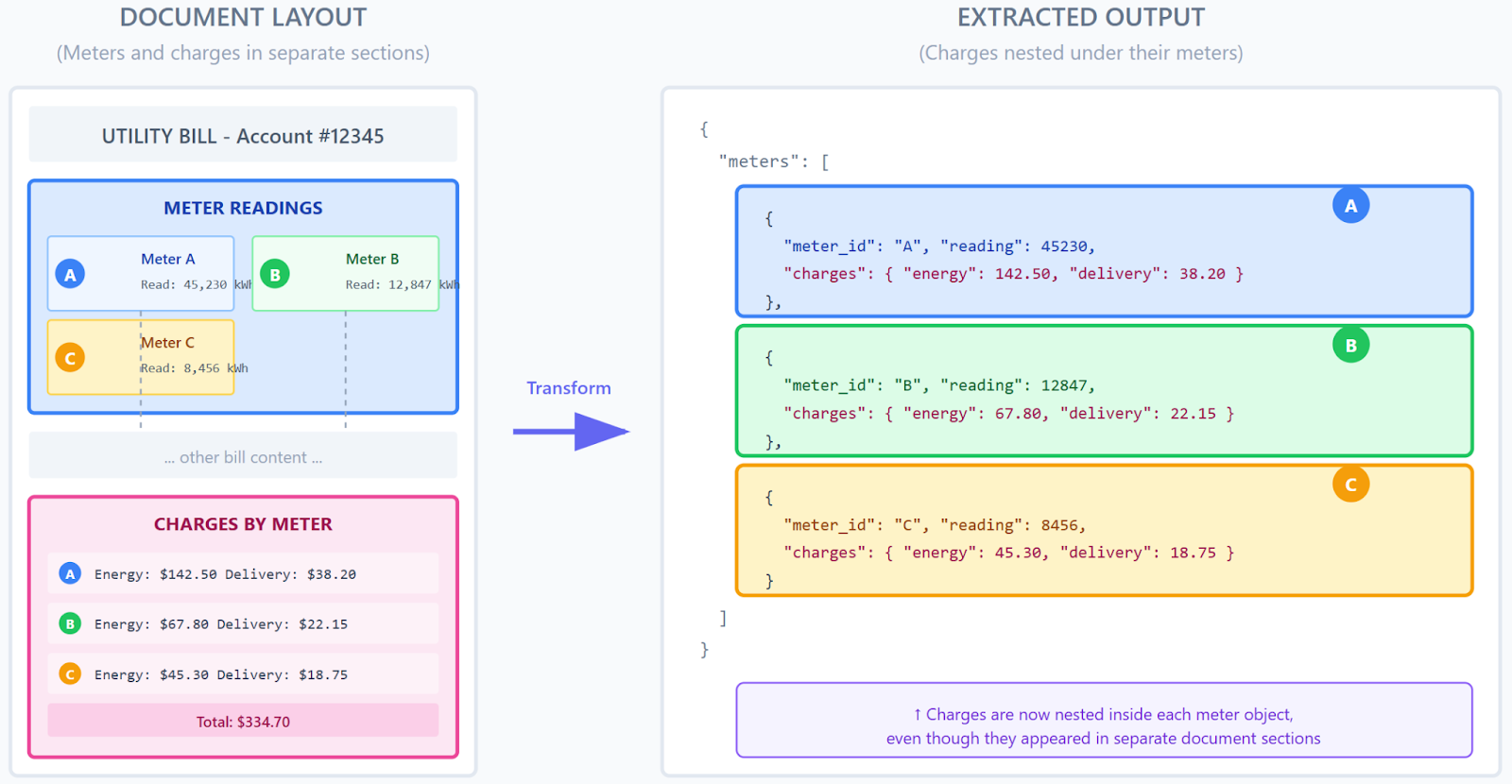
Why layout-based extraction rather than LLM-based extractions? The complexity of the sections and the strictness of the schema requirements made it the clear choice. As their implementation lead put it: "LLMs aren’t great at extracting long lists of repeating data. It's quicker and more reliable to do it with layout."
The results: From weeks to minutes
Within three months of launching their first templates, Company A's operations team reported feeling the lift. Templates that once took two weeks to build now come online far faster. Bills that required manual intervention now process automatically. Most importantly, the data arrives in exactly the schema their downstream systems expect.
Clarifying schema requirements was a key part of the partnership model. Understanding what data to pull, how to pull it, and what edge cases to handle took the longest to get right, because the correspondence between company A’s required output schema versus the document content wasn’t usually obvious. But once that foundation was established, the team hit a sustainable rhythm. Company A can now scale their extraction capacity without the engineering burden that strained their internal system.
Company B: Analytics at document scale
Company B is a technology consultancy that offers, among other services, telecom expense management analytics. They parse bills and build dashboards that help their clients understand spending patterns, such as where costs are increasing, which accounts are driving charges, and how usage breaks down across hundreds of phone lines.
The challenge: Documents measured in tens of thousands of pages
Company B's challenge wasn't format variety, it was sheer document size. A single telecom bill from a large enterprise client might contain 20,000 pages documenting hundreds of phone numbers, each with its own call logs, invoices, and international usage details.
Their internal solution couldn't handle documents at this scale. They evaluated multiple vendors, but none could solve the large document problem. They needed a partner willing to engineer custom solutions and commit to a long-term relationship. Switching document processing infrastructure is painful, and they wanted to make this decision once.
The solution: Custom engineering for massive documents
Company B's implementation required custom engineering from the Sensible team. The approach: intelligent document splitting. Rather than processing a 30,000-page document as a single unit, the system identifies logical split points—typically section headers—and processes chunks in parallel before unifying the results.
This divide-and-conquer strategy works because telecom bills, despite their length, have consistent internal structure. Headers indicate new sections; within each section, the data follows predictable patterns. If a header changes unexpectedly, the Sensible system flags it, but that's rare.
Another key feature: layout linearization. Some bill pages use a "snake" layout where content flows in multiple columns. The Sensible team built preprocessing that converts these complex layouts into single-column formats, ensuring sections break correctly and data associates with the right account.
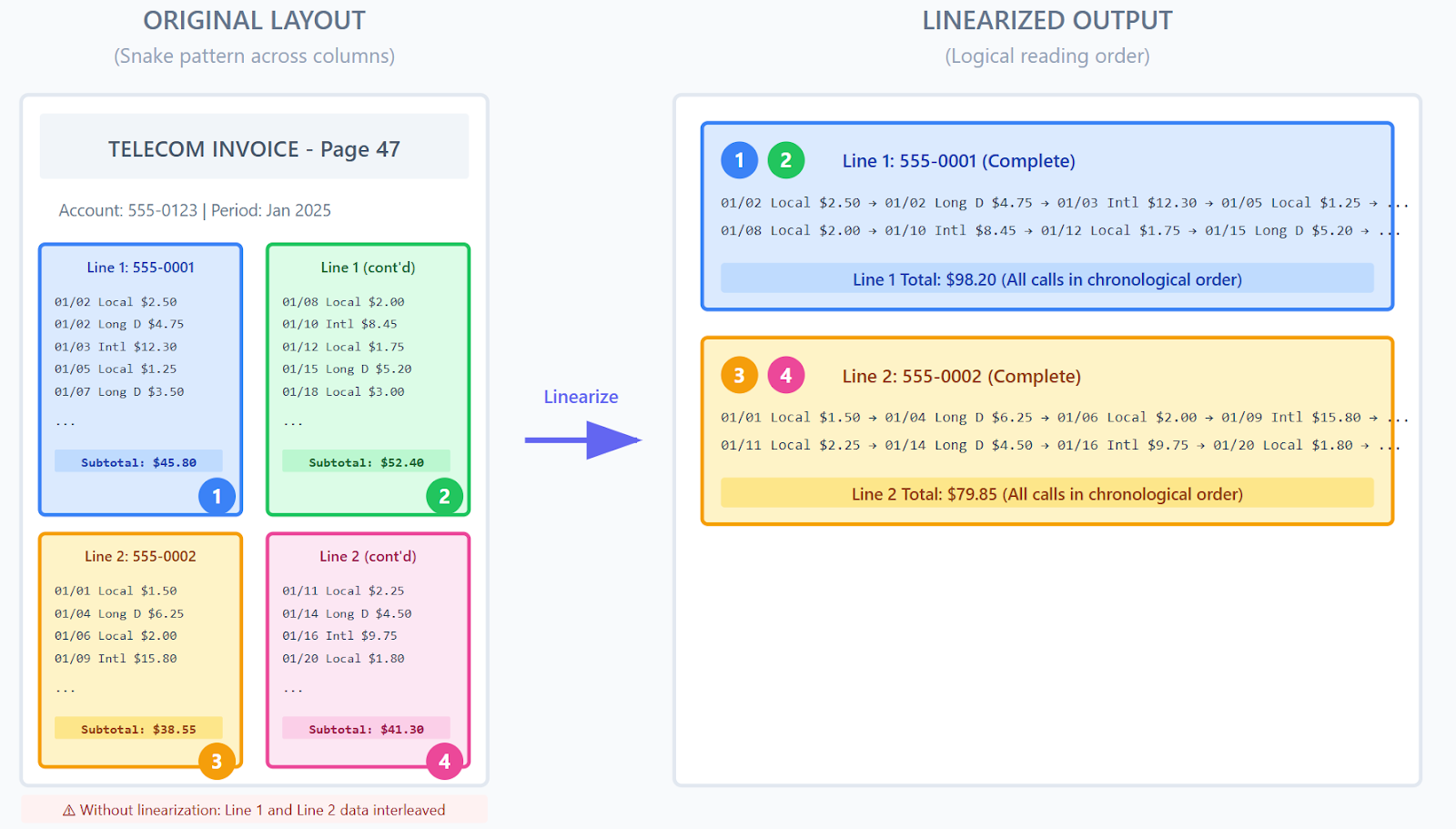
The extraction requirements themselves are straightforward but extensive. Company B wants everything: every phone number, every call log, every charge detail. Where Company A focuses on high-level auditing (do the line items add up to the total?), Company B needs granular data to power analytics dashboards that answer questions like "How much did international calls increase this quarter?"
The results: A scalable foundation for growth
Company B now processes documents that would have been impossible with their previous system. The engineering investment paid off: once the splitting and linearization infrastructure was in place, adding new carrier formats became relatively simple. The document structure is consistent; it's just a matter of building configurations for each carrier's specific layout.
The relationship operates through biweekly meetings and dedicated Slack channels, with a Sensible engineer in direct contact with Company B's engineering lead. It's the kind of deep technical partnership that made Company B comfortable going all in on this decision.
Two paths to the same destination
These implementations reveal how the same document category—utility and telecom bills—can demand fundamentally different approaches:
Company A optimized for format breadth and schema precision. With 2,000+ carriers and strict downstream requirements, they needed configurations that handle massive variation while delivering predictable, auditable output. Managed services let them scale without rebuilding their engineering team.
Company B optimized for document depth and data granularity. With documents stretching to tens of thousands of pages, they needed custom engineering to make extraction physically possible. Once that infrastructure existed, the extraction itself was relatively straightforward.
Both chose deterministic, layout-based extraction over LLM approaches—but for different reasons:
Company A: Schema requirements were too strict and sections too complex for LLMs to reliably interpret. The precision of layout-based methods guaranteed the exact output format their systems required.
Company B: Documents were too long and too dense. Telecom bills pack enormous amounts of small text into compact layouts. Layout-based extraction handles this complexity more reliably than LLMs, which can struggle with visual density.
Key takeaways for bill processing automation
If you're evaluating solutions for utility or telecom bill extraction:
- Assess your primary constraint: Is it format variety (hundreds of carriers) or document scale (thousands of pages)? The answer shapes your entire implementation strategy.
- Consider schema complexity early: If downstream systems require precise, conditional schemas—meters with readings handled differently than meters without—build that logic into your extraction design from the start.
- Plan for partnership: Both companies emphasized that interpretation took the longest. Understanding what to extract, how to handle edge cases, and what the output should look like requires close collaboration between your team and your extraction partner.
Evaluate LLM vs. deterministic honestly: LLMs work well for short documents with clear field labels. Dense, complex bills with strict schema requirements often benefit from deterministic approaches that guarantee consistent output.
Book a demo to discuss your bill processing requirements, or explore our managed services to see how we can handle template creation and maintenance for you.

.png)

